
ML-Assisted Data Labelling Services: Keystone for Large Language Model Training
Data labeling stays the lifeline of efficient massive language mannequin (LLM) coaching and optimization. Pre-trained LLMs present spectacular capabilities however nonetheless have appreciable gaps between their generic data and the specialised necessities of real-life functions.
Raw computational energy connects to sensible utility via knowledge labeling. Pre-trained fashions want labeled examples to specialise in particular duties like buyer help, authorized recommendation, or product suggestions. These fashions can tackle domain-specific challenges via fastidiously labeled knowledge that common coaching can’t clear up.
Data labeling goes past easy performance. It shapes LLMs to match human values. Modern fashions have to be correct, useful, innocent, and trustworthy. These qualities emerge from human suggestions and desire modeling methods that depend on structured labeling processes.
Traditional knowledge labeling strategies fall brief as LLMs turn out to be extra superior. Model evolution has modified the character of annotation fully. That’s why companies must rethink their knowledge labeling methods. Modern LLM growth requires subtle approaches that seize human preferences and area data effectively.
Modernize LLM Training with ML-Assisted Data Labeling Services
ML-assisted knowledge labeling has modified how organizations put together coaching knowledge for massive language fashions. Traditional strategies relied on human annotators alone. The new strategy blends machine studying algorithms into the labeling workflow to enhance effectivity and high quality.
ML-assisted knowledge labeling makes use of skilled machine studying fashions that create authentic labels for datasets. Human annotators evaluation and refine these labels afterward. This two-step course of eliminates guide work whereas conserving high quality requirements excessive. Several knowledge labeling corporations have created methods that change the way in which LLMs are skilled and optimized.
Entity Recognition: Named entity recognition duties use gazetteers, lists of entities, and their sorts to identify frequent entities robotically. Human annotators can then deal with complicated or unclear instances. This makes the entire course of extra environment friendly.
Text Summarization: Text summarization fashions shine when working with longer passages. Data labeling corporations use ML fashions to identify key sentences or create shorter variations of lengthy texts. This helps human annotators spend much less time on sentiment evaluation or classification duties.
Data Augmentation: Data augmentation strategies assist create bigger coaching datasets with out a lot guide work. AI knowledge labeling providers use methods like paraphrasing, again translation, and synonym substitute to create artificial examples. These examples assist make fashions extra sturdy.
Weak supervision allows fashions to study from noisy or incomplete knowledge. To cite an occasion, distant supervision makes use of labeled knowledge from related duties to grasp relationships in unlabeled content material. This method works significantly properly for LLM coaching.
GPT-4 and different benchmark LLMs have revolutionized how we annotate knowledge. These superior fashions generate labels robotically. Human annotators now primarily test high quality as an alternative of making labels from scratch.
This creates a constructive cycle. Better labeling results in extra high-quality coaching knowledge. This knowledge creates extra succesful fashions that assist with complicated labeling duties. Organizations can now put together huge datasets for state-of-the-art language fashions extra successfully than ever earlier than.
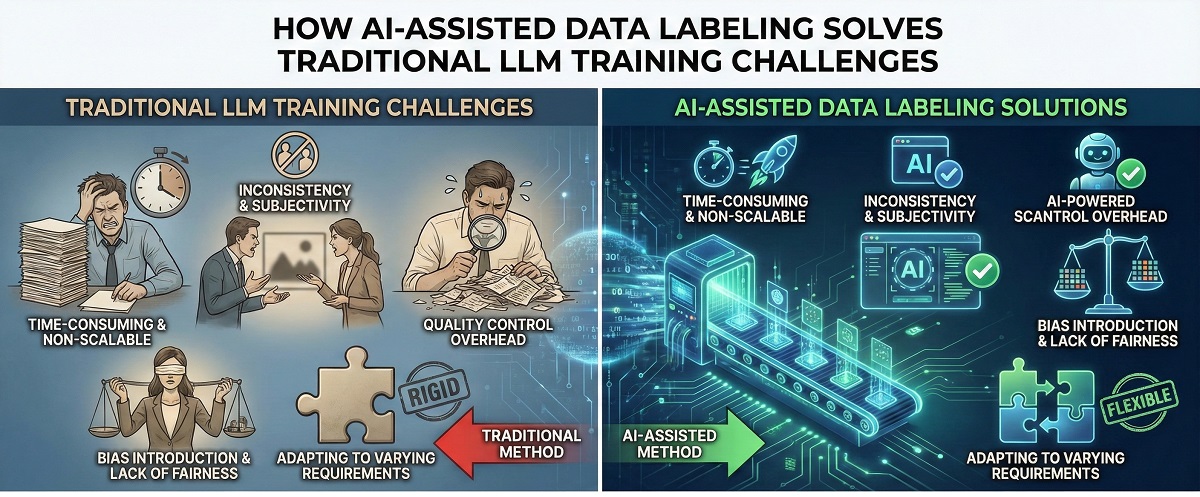
How AI-Assisted Data Labeling Solves Traditional LLM Training Challenges
Large language fashions pose distinctive challenges to conventional knowledge labeling processes. AI-assisted knowledge labeling gives possible options to those ongoing issues. These options create simplified processes that assist develop subtle LLMs.

1. Time-Consuming and Non-Scalable
Dataset measurement and complexity make guide annotation impractical. Manual annotation methods can’t handle the various volumes of information required to coach efficient language fashions. Intelligent labeling instruments tackle this drawback by automating repetitive duties with out compromising high quality. Data labeling corporations use lively studying algorithms to select probably the most precious examples for human evaluation. This sensible use of human experience turns an unimaginable process right into a manageable course of that handles large datasets.
2. Inconsistency and Subjectivity
Machine studying algorithms apply the identical standards to all datasets, not like guide annotators who may execute pointers in a different way resulting from tiredness or private bias. This precision minimizes the variances frequent in guide labeling strategies. Professionals from knowledge labeling outsourcing companies make the most of normal algorithmic approaches to make sure label precision all through initiatives. Standard annotation pointers and sensible screening assist human annotators stay aligned. This strategy eliminates the interpretation issues that usually occur in manual-only workflows.
3. Quality Control Overhead
Traditional high quality checks depend on post-labeling evaluations or evaluating totally different annotators’ work, a course of that creates further work and delays. AI-assisted techniques construct high quality checks into your entire course of. Smart validation algorithms catch potential errors immediately and forestall greater high quality points. Automated validation instruments discover outliers and inconsistencies via cross-validation and statistical sampling. This strategy reduces the evaluation work wanted in conventional strategies.
4. Bias Introduction and Lack of Fairness
AI knowledge labeling instruments include built-in options to identify and alleviate potential biases. These techniques stop unconscious biases from human annotators via various coaching knowledge necessities and automatic equity checks. Regular dataset audits look particularly for bias patterns to maintain equity a high precedence all through the labeling course of.
5. Adapting to Varying Requirements
AI-assisted labeling handles totally different knowledge sorts and sophisticated necessities. Specialized instruments for varied codecs (textual content, pictures, audio) adapt to consumer wants with out redesigning the entire workflow. The system’s potential to extract clear, unambiguous guidelines from normal procedures creates expandable options that work for totally different domains and use instances.
Key Ways Data Labeling Outsourcing Firms Modernize LLM Training and Optimization
Data labeling corporations are revolutionizing LLM growth. They use machine studying algorithms all through the annotation course of. Their progressive approaches clear up key challenges and create extra environment friendly, correct coaching strategies.

I. Active Learning for Intelligent Label Selection
Data labeling companies use lively studying algorithms to select probably the most precious knowledge factors that want human annotation. The techniques don’t label randomly. They flag samples the place mannequin confidence is lowest or these close to determination boundaries. This focused strategy cuts labeling prices and directs human experience precisely the place wanted.
II. Semi-Supervised and Weak Supervision Techniques
AI knowledge labeling providers maximize worth from restricted sources by combining small, labeled datasets with bigger, unlabeled ones. Self-training strategies create pseudo labels for assured predictions. Co-training makes use of a number of mannequin views to spice up accuracy. Distant supervision finds relationships from associated duties, which creates highly effective studying indicators with out direct annotation.
III. Automated Quality Assurance with ML
Quality management has developed past human evaluation with automated validation techniques. ML algorithms spot inconsistencies and flag potential errors. They establish edge instances that want further consideration. This reside verification stops high quality points from spreading via the dataset.
IV. ML Feedback Loops for Continuous Improvement
Models get higher via iterative refinement. Annotators’ corrections feed again into the system and create a cycle of ongoing enchancment. Each suggestions spherical helps the mannequin higher perceive complicated patterns.
V. Scalability and Distributed Labeling Infrastructure
Modern labeling platforms help team-wide distributed workflows. These techniques preserve every part constant via shared pointers. Specialized annotators can deal with their experience areas. So even large datasets could be processed effectively with out high quality loss.
ML-assisted knowledge labeling has reshaped the scene of enormous language mannequin growth. This piece reveals how conventional annotation approaches now not work for fashionable LLMs. Scalability limits, systemic issues with consistency, and excessive prices have made a elementary change essential as an alternative of small enhancements.
LLM growth will proceed to rely upon subtle knowledge labeling providers. Unsupervised studying methods preserve advancing. Yet, specialised data and human alignment from cautious annotation stay essential. Companies that turn out to be expert at these superior labeling strategies will form the following technology of language fashions. These fashions will mix uncooked computational energy with sensible use in quite a lot of fields.
The publish ML-Assisted Data Labelling Services: Keystone for Large Language Model Training appeared first on Datafloq News.